说话者和声纹识别: 开源库的力量
前言
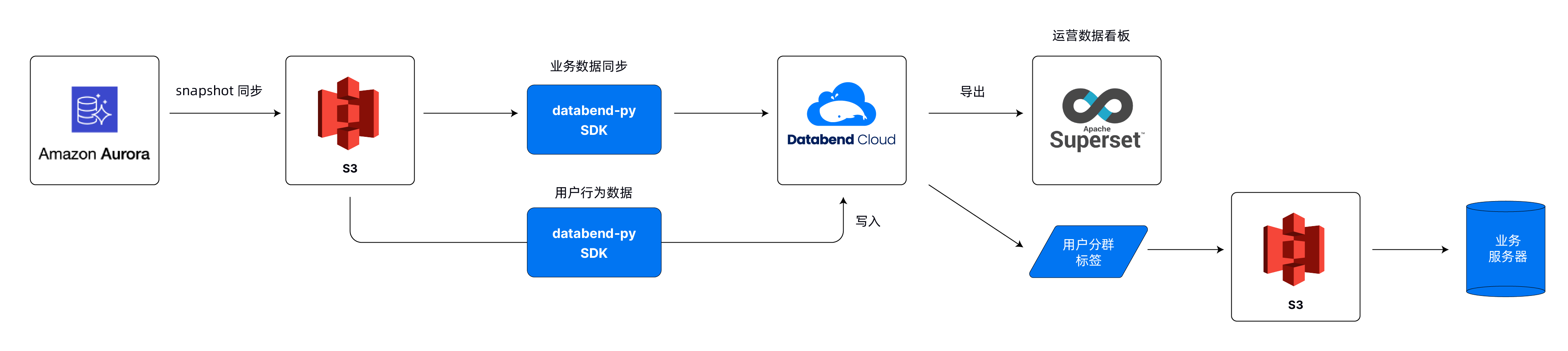
本文将介绍六个不同的开源库,它们各自在音视频处理,计算机视觉,深度学习和语音识别领域有着重要作用。这些库包括PJSIP、ALIZE、WebRTC、OpenCV、TensorFlow和Kaldi,我们将会探索每一个库中特定的功能和应用。
欢迎订阅专栏:C++风云录
文章目录
- 说话者和声纹识别: 开源库的力量
- 前言
- 声纹识别与语音加密
- 1. PJSIP:开源跨平台音频/视频通信库
- 1.1 C++ API的作用
- 1.1.1 语音加密
- 1.1.2 通信应用
- 2. ALIZE:用于说话者识别和声纹识别的C++库
- 2.1 说话者识别
- 2.2 声纹识别
- 3. WebRTC: 实时通信协议库
- 3.1 音频处理
- 3.1.1 噪声消除
- 3.1.2 回声消除
- 3.2 视频处理
- 3.2.1 视频编解码
- 3.2.2 视频捕获和渲染
- 4. OpenCV:开源计算机视觉库
- 4.1 图像处理
- 4.1.1 滤波器
- 4.1.2 边缘检测
- 4.2 视频分析
- 4.2.1 目标跟踪
- 4.2.2 动态场景理解
- 5. TensorFlow:开源深度学习库
- 5.1 训练神经网络模型
- 5.2 使用训练好的模型进行预测
- 6. Kaldi:专注于语音识别的软件工具包
- 6.1 特征提取
- 6.1.1 MFCC
- 6.1.2 PLP
- 6.2 声学模型
- 6.2.1 GMM-HMM
- 6.2.2 DNN-HMM
- 总结
声纹识别与语音加密
1. PJSIP:开源跨平台音频/视频通信库
PJSIP是一个免费开源的音频和视频通信协议栈库,提供了丰富的功能以支持各种实时交互应用。PJSIP支持多种操作系统和硬件平台,包括Windows, Linux, macOS, iOS和Android。
1.1 C++ API的作用
PJSIP库提供了一套API接口,方便开发人员快速开发音频和视频通信应用。这些API提供了对SIP, SDP, RTP, STUN, TURN, and ICE等协议的支持,并且可以轻松地扩展到其他协议。
1.1.1 语音加密
在音视频通信中,保护通信内容的安全是非常重要的。PJSIP提供了语音加密的机制,可以有效防止通话内容被窃听。以下是一个简单的C++代码示例,演示如何使用PJSIP的API进行语音加密:
#include <pjmedia/transport_srtp.h>
// 初始化SRTP设置
pjmedia_srtp_setting srtpOpt;
pjmedia_srtp_setting_default(&srtpOpt);
srtpOpt.close_member_tp = PJ_TRUE;
// 创建SRTP传输
status = pjmedia_transport_srtp_create(pjmedia_endpt_instance(), transport, &srtpOpt, &srtp_transport);
if (status != PJ_SUCCESS) {
// 错误处理
}
// 启动SRTP传输
status = pjmedia_transport_srtp_start(srtp_transport, &crypto, NULL);
if (status != PJ_SUCCESS) {
// 错误处理
}
详细信息请参考PJSIP 官方文档
1.1.2 通信应用
在PJSIP库中,开发者可以使用一些基本的组件来创建自己的通信应用。下面的C++代码示例展示了如何使用PJSIP的API创建一个简单的通信应用客户端:
#include <pjsua-lib/pjsua.h>
// 初始化库
pjsua_create();
// 创建PJSUA配置
pjsua_config cfg;
pjsua_config_default(&cfg);
// 初始化并启动PJSUA
pjsua_init(&cfg, NULL, NULL);
// 添加SIP账户
pjsua_acc_config acc_cfg;
pjsua_acc_config_default(&acc_cfg);
pj_str_t uri = pj_str((char *)"sip:your_sip_server");
pjsua_acc_add(&acc_cfg, PJ_FALSE, NULL);
// 开始处理事件
pjsua_start();
详细信息请参考PJSIP 官方文档
2. ALIZE:用于说话者识别和声纹识别的C++库
Alize是一个开源平台,它是为了使说话者识别、说话者分析和说话者跟踪变得容易。该库专门设计用于处理大量的数据和实验。
2.1 说话者识别
说话者识别是指通过分析和比较声音信号中的特征参数,确定当前说话者的身份。以下是一个简单的使用ALIZE进行说话者识别的C++代码例子:
#include "alize.h"
int main() {
alize::MixtureServer ms;
ms.loadMixtureFile("path_to_mixture_file");
alize::FeatureServer fs(config, "path_to_feature_file");
alize::Feature f;
while (fs.readFeature(f)) {
real_t score = ms.computeTopGaussLike(f);
std::cout << "Score: " << score << std::endl;
}
return 0;
}
更多详情,请参考ALIZE官方文档.
2.2 声纹识别
声纹识别是通过分析和比较声音信号中的特征参数,确定某段语音是否由某个特定的人发出。以下是一个简单的使用ALIZE进行声纹识别的C++代码例子:
#include "alize.h"
int main() {
alize::MixtureServer ms;
ms.loadMixtureFile("path_to_mixture_file");
alize::FeatureServer fs(config, "path_to_feature_file");
alize::Feature f;
while (fs.readFeature(f)) {
real_t score = ms.computeTopGaussLike(f);
std::cout << "Score: " << score << std::endl;
if (score > threshold) {
std::cout << "Voiceprint recognized!" << std::endl;
} else {
std::cout << "Voiceprint not recognized." << std::endl;
}
}
return 0;
}
更多详情,请参考ALIZE官方文档.
3. WebRTC: 实时通信协议库
WebRTC (Web Real-Time Communication) 是一套开源的实时通信技术,它包含了音频、视频通话和数据共享等功能。这一协议库可以让你在网页或者移动应用中嵌入视频聊天等实时通信功能。
官方网站
3.1 音频处理
在WebRTC中,音频处理是非常重要的部分,其中涉及到噪声消除和回声消除等关键技术。
3.1.1 噪声消除
噪声消除是用于减少背景噪声、风声、电器噪声等的技术。下面是一个简单的C++示例代码:
#include <webrtc/modules/audio_processing/include/audio_processing.h>
// 创建AudioProcessing对象
webrtc::AudioProcessing* apm = webrtc::AudioProcessing::Create();
// 开启噪声消除
apm->noise_suppression()->Enable(true);
更多信息和示例代码可以参考WebRTC官方文档
3.1.2 回声消除
回声消除是用于防止扬声器的声音被麦克风再次捕获,形成回声。下面提供一个示例代码:
#include <webrtc/modules/audio_processing/include/audio_processing.h>
// 创建AudioProcessing对象
webrtc::AudioProcessing* apm = webrtc::AudioProcessing::Create();
// 开启回声消除
apm->echo_cancellation()->enable_drift_compensation(true);
3.2 视频处理
视频处理也是WebRTC中的重要环节,包括视频编解码和视频捕获与渲染。
3.2.1 视频编解码
视频编解码是将原始视频流转换为压缩的格式(编码)以及将压缩的格式转换回原始视频流(解码)。以下提供一个基本的编解码示例代码:
#include <webrtc/video_frame.h>
#include <webrtc/media/base/videocodec.h>
// 创建编解码器
webrtc::VideoCodec codec;
codec.codecType = webrtc::kVideoCodecVP8;
webrtc::VideoFrame frame = ...; // 从某个地方获取一帧视频
// 编码一帧
webrtc::EncodedImage encoded_image;
webrtc::CodecSpecificInfo codec_specific_info;
webrtc::RTPFragmentationHeader fragmentation_header;
int32_t result = encoder->Encode(frame, &codec_specific_info, &fragmentation_header);
更多关于视频编解码的信息可以参考WebRTC官方文档
3.2.2 视频捕获和渲染
#include <webrtc/api/video_codecs/video_encoder.h>
#include <webrtc/api/video/video_frame.h>
#include <webrtc/api/video/video_sink_interface.h>
// 创建VideoTrackSource对象,用于从摄像头获取视频数据
rtc::scoped_refptr<webrtc::VideoTrackSourceInterface> video_source =
peer_connection_factory->CreateVideoSource();
// 创建VideoTrack对象,将其添加到PeerConnection中
rtc::scoped_refptr<webrtc::VideoTrackInterface> video_track =
peer_connection_factory->CreateVideoTrack(kStreamLabel, video_source);
// 设置视频数据的接收端(例如一个窗口)
video_track->AddOrUpdateSink(video_window, rtc::VideoSinkWants());
更多关于视频捕获和渲染的内容可以查看WebRTC官方文档 。
4. OpenCV:开源计算机视觉库
OpenCV是一个基于BSD许可(也可以说是商业许可)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级且高效——由一系列 C 函数和少量 C++ 类构成,提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。官网链接:OpenCV
4.1 图像处理
4.1.1 滤波器
滤波器是一种可以改变图像强度(如亮度或暗度)的方法,在OpenCV中,我们可以通过如下代码实现滤波操作:
#include <opencv2/opencv.hpp>
int main( int argc, char** argv )
{
// 加载原始图像
cv::Mat src = cv::imread(argv[1], 1);
// 均值滤波
cv::Mat dst;
blur(src, dst, cv::Size(5,5));
return 0;
}
更多详细信息可参考OpenCV滤波器官方文档。
4.1.2 边缘检测
边缘检测是识别图像边界的重要步骤,以下代码展示了如何使用OpenCV进行边缘检测:
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
int main(int argc, char** argv)
{
cv::Mat src, edge, gray;
// 读入图片,转为灰度图象
src = imread(argv[1], 1);
cvtColor(src, gray, CV_BGR2GRAY);
// 使用Canny进行边缘检测
Canny(gray, edge, 50, 150, 3);
return 0;
}
关于边缘检测的更多细节,请访问OpenCV边缘检测官方文档。
4.2 视频分析
OpenCV对视频的支持也非常完善,包括目标跟踪、动态场景理解等功能。
4.2.1 目标跟踪
目标跟踪是计算机视觉中的一个重要部分,OpenCV提供了简单易用的API进行目标跟踪。以下就是一个简单的例子:
#include <opencv2/opencv.hpp>
int main(int argc, char** argv)
{
cv::Mat frame;
// 设置初始化边界框的位置
cv::Rect2d bbox(287, 23, 86, 320);
// 加载视频
cv::VideoCapture video(argv[1]);
// 创建KCF跟踪器
cv::Ptr<cv::Tracker> tracker = cv::TrackerKCF::create();
// 初始化跟踪器
tracker->init(frame, bbox);
while(video.read(frame))
{
// 更新跟踪结果
tracker->update(frame, bbox);
// 画出边界框
rectangle(frame, bbox, cv::Scalar(255, 0, 0), 2, 1);
// 显示结果
imshow("Tracking", frame);
if(cv::waitKey(1) == 27) break;
}
return 0;
}
关于目标跟踪的更多信息,请参考OpenCV官方文档。
4.2.2 动态场景理解
OpenCV 提供了背景消除等动态场景理解的方法。例如,可以使用 createBackgroundSubtractorMOG2() 创建一个背景消除器。
Ptr<BackgroundSubtractor> pMOG2 = createBackgroundSubtractorMOG2();
pMOG2->apply(frame, fgmask);
5. TensorFlow:开源深度学习库
TensorFlow是一个强大的开源深度学习库,支持多种平台。它由Google Brain团队开发,用于进行机器学习和神经网络研究。
5.1 训练神经网络模型
首先,我们需要训练一个神经网络模型。以下是一个简单的神经网络模型训练的C++实例代码:
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/platform/env.h"
using namespace tensorflow;
int main(int argc, char* argv[]) {
// Initialize a TensorFlow session.
Session* session;
Status status = NewSession(SessionOptions(), &session);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Load the data
Tensor x(DT_FLOAT, TensorShape({3, 3}));
auto x_flat = x.flat<float>();
for (int i = 0; i < x_flat.size(); ++i) {
x_flat(i) = 1.0;
}
// Run the session
std::vector<Tensor> outputs;
status = session->Run({{"x", x}}, {"y"}, {}, &outputs);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Print the result
cout << outputs[0].flat<float>() << "\n";
// Free any resources used by the session
session->Close();
delete session;
}
以上代码初始化了一个TensorFlow会话,然后加载数据并运行会话。
5.2 使用训练好的模型进行预测
当我们有一个训练好的模型后,我们就可以用它来进行预测。以下是一个使用训练好的模型进行预测的C++实例代码:
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/platform/env.h"
using namespace tensorflow;
int main(int argc, char* argv[]) {
// Initialize a new session
Session* session;
Status status = NewSession(SessionOptions(), &session);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Load the trained model
GraphDef graph_def;
status = ReadBinaryProto(Env::Default(), "./trained_model.pb", &graph_def);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Add the graph to the session
status = session->Create(graph_def);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Run the session with input, check the output
std::vector<Tensor> outputs;
Tensor x(DT_FLOAT, TensorShape({3, 5}));
auto x_flat = x.flat<float>();
for (int i = 0; i < x_flat.size(); ++i) {
x_flat(i) = 1.0;
}
status = session->Run({{"x", x}}, {"y"}, {}, &outputs);
if (!status.ok()) {
cout << status.ToString() << "\n";
return 1;
}
// Print the result
cout << outputs[0].flat<float>() << "\n";
// Free any resources used by the session
session->Close();
delete session;
}
以上代码首先初始化一个新的TensorFlow会话,然后加载训练好的模型,并使用模型进行预测。
6. Kaldi:专注于语音识别的软件工具包
Kaldi是一个由Daniel Povey和他的团队开发的开源语音识别工具包。它提供了一套完整的语音识别系统,包括特征提取、声学模型、解码器和训练工具等。Kaldi的主页链接是这里。
6.1 特征提取
在Kaldi中,有两种主要的特征提取方法:MFCC(Mel频率倒谱系数)和PLP(感知线性预测)。下面我们将会分别进行介绍。
6.1.1 MFCC
MFCC是一种广泛使用的语音特征提取方法。以下是一个C++例子,展示了如何在Kaldi中提取MFCC特征:
#include "feat/mfcc.h"
void ComputeMFCC(KaldiInputStream& input, Matrix<BaseFloat>& mfcc_features) {
MfccOptions options;
Mfcc mfcc(options);
WaveData wave_data;
wave_data.Read(input);
mfcc.Compute(wave_data.Data(), 1.0, &mfcc_features);
}
6.1.2 PLP
PLP是另一种常用的语音特征提取方法。以下是一个C++例子,展示了如何在Kaldi中提取PLP特征:
#include "feat/plp.h"
void ComputePLP(KaldiInputStream& input, Matrix<BaseFloat>& plp_features) {
PlpOptions options;
Plp plp(options);
WaveData wave_data;
wave_data.Read(input);
plp.Compute(wave_data.Data(), 1.0, &plp_features);
}
6.2 声学模型
Kaldi支持多种声学模型,包括GMM-HMM和DNN-HMM。
6.2.1 GMM-HMM
在Kaldi中,可以通过以下方式来构建和训练GMM-HMM模型:
#include "gmm/am-diag-gmm.h"
#include "hmm/hmm-utils.h"
AmDiagGmm am_gmm;
TransitionModel trans_model;
// 构建和训练GMM-HMM模型
TrainHmmModel(features, labels, &am_gmm, &trans_model);
// 保存模型
WriteKaldiObject(am_gmm, "gmm.mdl", binary);
WriteKaldiObject(trans_model, "trans.mdl", binary);
6.2.2 DNN-HMM
在Kaldi中,DNN-HMM模型的构建和训练可以通过以下方式进行:
#include "nnet3/nnet-utils.h"
#include "hmm/hmm-utils.h"
Nnet nnet;
TransitionModel trans_model;
// 构建和训练DNN-HMM模型
TrainDnnHmmModel(features, labels, &nnet, &trans_model);
// 保存模型
WriteKaldiObject(nnet, "nnet.mdl", binary);
WriteKaldiObject(trans_model, "trans.mdl", binary);
更多关于Kaldi的使用和详细信息,请参考其官方文档。
总结
通过对PJSIP、ALIZE、WebRTC、OpenCV、TensorFlow和Kaldi六个开源库的深入研究,我们得到的结论是,这些开源库在各自的领域中都显示出了强大的功能。它们的存在极大地推动了技术的进步,并为相关领域的专业人士提供了有效的工具。